[Coding037] LeetCode 82
Remove Duplicates from Sorted List II
Ben
2024.03.29
Get the knowledge flowing and circulating! :)
目录
※ 本题收获
当链表中需要用到2个节点时,变量的参考命名可以是:
slow, fast
prev, cur
当链表中需要用到3个节点时,变量的参考命名可以是:
prev, slow, fast
p, q, r (不太好,无法知道先后顺序)
题目:82. Remove Duplicates from Sorted List II
Given the head of a sorted linked list, delete all nodes that have duplicate numbers, leaving only distinct numbers from the original list. Return the linked list sorted as well.
Example 1:
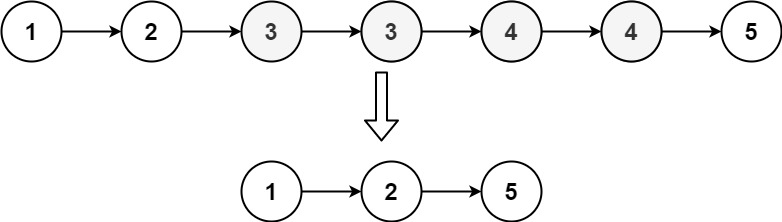
xxxxxxxxxx21Input: head = [1,2,3,3,4,4,5]2Output: [1,2,5]
Example 2:
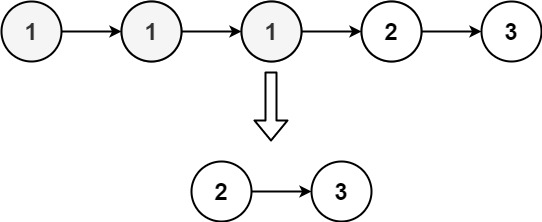
xxxxxxxxxx21Input: head = [1,1,1,2,3]2Output: [2,3]
Constraints:
The number of nodes in the list is in the range
[0, 300].-100 <= Node.val <= 100The list is guaranteed to be sorted in ascending order.
代码1(配 · 手绘过程图)
xxxxxxxxxx401/**2 * Definition for singly-linked list.3 * public class ListNode {4 * int val;5 * ListNode next;6 * ListNode() {}7 * ListNode(int val) { this.val = val; }8 * ListNode(int val, ListNode next) { this.val = val; this.next = next; }9 * }10 */11class Solution {12 public ListNode deleteDuplicates(ListNode head) {13 if (head == null || head.next == null) return head;14
15 ListNode dummy = new ListNode(0);16 dummy.next = head;17
18 ListNode p = dummy;19 while (p.next != null && p.next.next != null)20 {21 ListNode q = p.next;22 ListNode r = q.next;23 if (q.val != r.val)24 {25 p = q;26 }27 else 28 { 29 while(r != null && q.val == r.val) // 这句很巧妙:一直向后判断!30 {31 r = r.next; // r后移32 } 33 p.next = r; // 把中间砍掉(头的下一个是尾)34 }35 }36
37 return dummy.next;38 39 }40}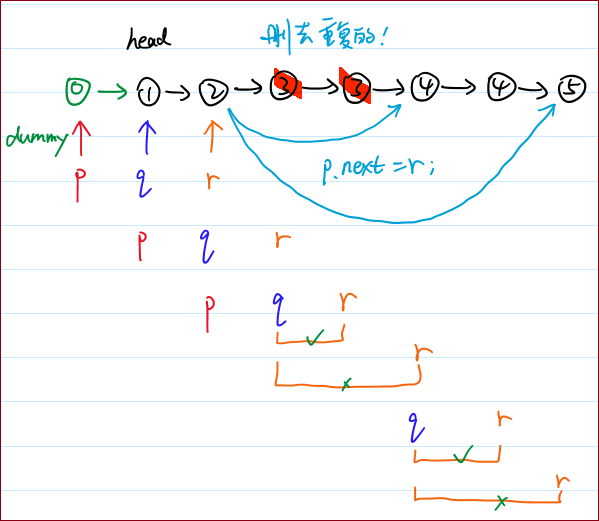
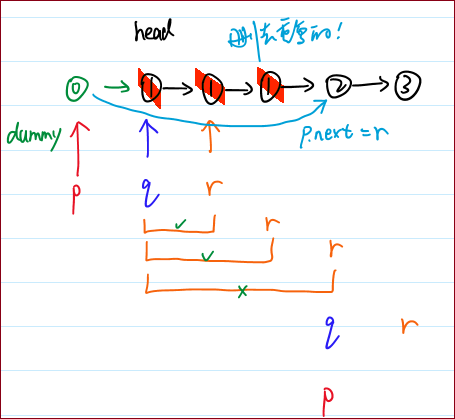
代码解读 | 评价
第23~34行非常重要。
这里先判断的是“不相等”的情况,比较巧妙。
第33行是核心。也就是上图中的浅蓝色线条指向的动作:实现了去重的操作。